AI in action
Product innovation
Tracing our impact
Marketplace principles
Inside scoop
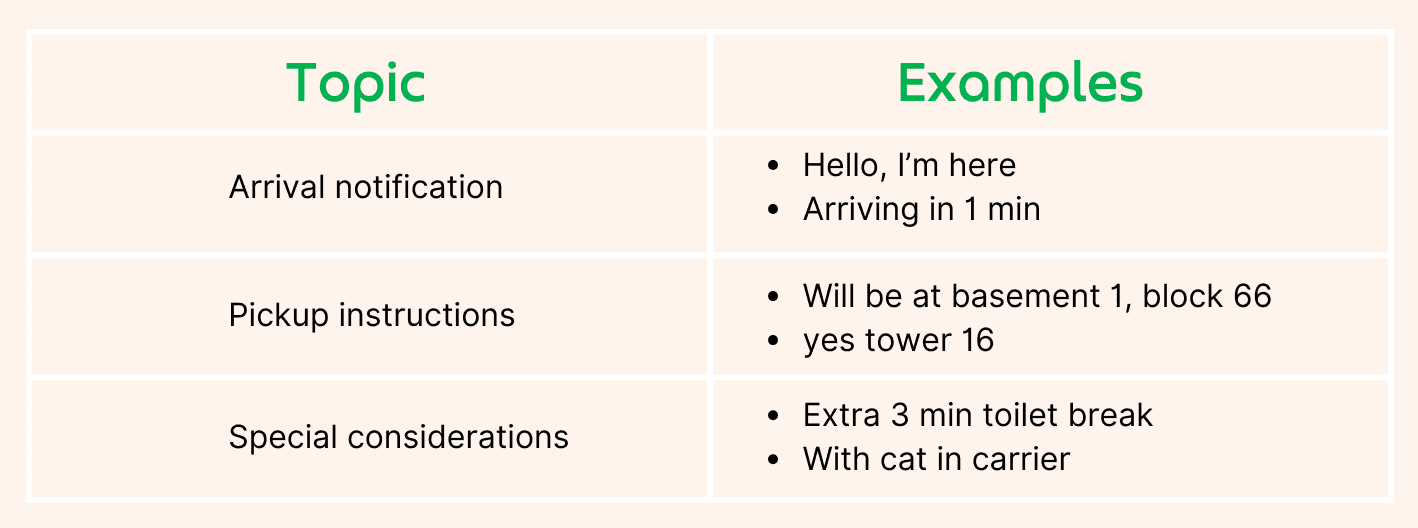
We made translations on GrabChat more accurate. Here’s how.
.
September 19, 2024
.
Regional
About
Consumer
Merchant
Enterprise
Quick Links

